AndroidのWebViewでバックグラウンドでの遅延実行を考える。
WebViewで読み込み後数秒DelayさせてからScriptをInjectionさせたいことってありますよね。動的に生成されるページなどである程度Delay挟んでからDOM取得したいとかそんな感じです*1。そんなとき手癖で以下のようなコードをまずは書いてみました。
private val script = """ setTimeout(() => { // ここにやりたいことを書く }, 5000); """.trimIndent() // 中略 webView.webViewClient = object: WebViewClient() { override fun onPageFinished(view: WebView?, url: String?) { super.onPageFinished(view, url) view?.loadUrl("javascript:$script") } }
フォアグラウンド動作時はこれでもいいのですが、バックグラウンドでは意図した動作になっていないことがlogcatの出力などから確認できました。ググったらJavaScript制御でのTimeout系動作がバックグラウンドに行ったら動作しないっぽい*2ようなのでWebViewの外で遅延制御するようにしてみます。
private val script = """ // ここにやりたいことを直接書く """.trimIndent() // 中略 webView.webViewClient = object: WebViewClient() { override fun onPageFinished(view: WebView?, url: String?) { super.onPageFinished(view, url) Handler(Looper.getMainLooper()).postDelayed({ view?.loadUrl("javascript:$script") }, 5000) } }
簡単な動作確認ではこれで動いているっぽいです。
ただ、確かTimer設定しない処理ってあまり時間は厳密に動いていなかったような気がするので、厳密にやるにはTimerでやるかフォアグラウンドでのJavaScript動作に任せるとかになるんですかね。
*1:正直あまり賢くはない方法だと思います。が、適当に作る、あるいは外部サイトに対して何かしたいときはこんなんでもいいのかなと。
*2:参考にしました: Android WebView 内の JavaScript で RxJS の bufferTime/timeout等 を使うと端末スリープ後5分経過で subscribe が来なくなる件
読んだ: Code Reading プレミアムブックス版
長い、手短に言って
- 流石に初版が2004年の本を今読むには古い、ただし歴史のある(Cの)コードを触る場合は読んで損はない
- 対象層がいまいちよくわからないが、これは私が業務でも5年くらい、非業務含めるともう15年くらいコード書いているからかもしれん
- 非業務経験があってある程度書けるプログラマが業務に入る前に読むのはアリ
出版社の紹介サイト
所感
本書は基本的にCで書かれたOSSコードを掲載し、それに対する形でコードの読み方を解説している。目次を読んでも分かるように、前半は基本制御構造やデータ構造の説明などとなっている。ここは(特にC中心に触っている)ある程度経験のあるプログラマであればboringであり、逆にそうでない者には難しすぎるように感じた。これが冒頭で対象層がいまいちよくわからないといった所以である。ある程度経験がある自負があり、Cを触っていて、かつデータ構造と言われてもピンとこないのであればこのあたりは理解しておいた方がいい。最近の言語であればデータ構造のあたりは標準ライブラリで提供されるので気にしないところではあるが……
また、掲載されているコードは古いと感じるものが多い。冒頭にK&R C仕様を考慮したコード(!)があり、以降もif構文でブロックを使用していないコードなどが目立つ。最近のコードは可読性やバグ防止のためif構文による命令が単一命令でもブロック化するのがほとんどであると勝手に思い込んでいるので、歴史のあるコードが多いのだなと感じた。これは裏を返せばUnixに古くからあるツールのコードを読むような場合は指針となるであろうということでもある。
7章以降は実プロジェクト寄りの話題が中心となる。が、これもある程度実務経験があるならば身につけている(つけていてほしい)ことなのではないかな。
この手の本を買うときはいくら名著と言われていても出版日や目次をしっかり確認して、得られるものがあるかどうか吟味しないとダメですね。
Control Flow Basedなdiffをとりたかった。[終]
もう随分前に作ったのに何も書いていなかった……
github.com
とりあえず作ったのはいいものの、(色々な意味で)これ業務で使うわけにはいかないよなぁ……となったのでお蔵入りです。
できること
こんな感じで比較できます。
/* bef.c */
#include <stdio.h>
#include <stdlib.h>
int main() {
int type;
type = rand() % 4;
if (type == 1) {
printf("hoge()");
printf("fuga()");
} else {
printf("piyo()");
printf("poyo()");
}
printf("foo()");
printf("bar()");
return 0;
}/* aft.c */
#include <stdio.h>
#include <stdlib.h>
int main() {
int type;
type = rand() % 4;
switch (type) {
case 1:
printf("hoge()");
// oops
break;
case 2:
printf("newHoge()");
break;
default:
printf("piyo()");
printf("poyo()");
break;
}
printf("foo()");
printf("bar()");
return 0;
}$ ./cfbdiff bef.c aft.c Function: "main" block deleted: printf ("hoge()"); printf ("fuga()"); Function: "main" block added: printf ("newHoge()"); Function: "main" block added: printf ("hoge()");
やっていること
GCCの-fdump-tree-cfgオプションで吐き出されるファイルをアドホックにゴリゴリの解析しているだけです。比較はBasic Block(参考: 基本ブロック - Wikipedia)の内容をハッシュ化することで行い、前後のBasic Block集合で片方にしか存在しないものを出力しています。
一応グラフとしての構造も持たせてはいるのですが、現状使っていません。図として出力したいとなったら使いますが、今のところそれはない見込み。
LLVMのswitchを解析してみたかった。
rutilicus.hatenablog.com
これの続きです。改めて解析対象のソースコードなど。
で、これを解析しようとしたコードがこれです。
#include <iostream> #include <map> #include <string> #include <list> #include <set> #include <algorithm> #include <llvm/IR/LLVMContext.h> #include <llvm/IR/Module.h> #include <llvm/IR/Instruction.h> #include <llvm/IR/Instructions.h> #include <llvm/IRReader/IRReader.h> #include <llvm/Support/SourceMgr.h> int main(int argc, char** argv) { llvm::LLVMContext context; llvm::SMDiagnostic err; std::unique_ptr<llvm::Module> module = llvm::parseIRFile("aft.ll", err, context); if (!module) { err.print(argv[0], llvm::errs()); return 1; } for (llvm::Function &function: module->getFunctionList()) { if (!function.isDeclaration()) { // Condition Id -> Condition String std::map<int, std::string> condIdStrMap; // Condition Id int condId = 0; // BasicBlock Name -> Block Condition Ids std::map<std::string, std::set<int>> blockCondsMap; // Condition sets derived from same origin Conditional Syntax std::list<std::set<int>> condSetSameOrigin; for (llvm::BasicBlock &block: function) { std::string currentBlockName = block.getName().data(); // remove unnecessary block conditions if (blockCondsMap.find(currentBlockName) == blockCondsMap.end()) { blockCondsMap[currentBlockName] = std::set<int>(); } std::list<int> allBlockConditions; for (int i: blockCondsMap[currentBlockName]) { allBlockConditions.push_back(i); } for (int i: allBlockConditions) { for (std::set<int> s: condSetSameOrigin) { if (s.find(i) != s.end() && std::all_of(s.begin(), s.end(), [&](int x) { return blockCondsMap[currentBlockName].find(x) != blockCondsMap[currentBlockName].end(); })) { std::for_each(s.begin(), s.end(), [&](int x) { blockCondsMap[currentBlockName].erase(x); }); } } } std::string blockConditionStr; if (blockCondsMap[currentBlockName].empty()) { blockConditionStr = "N/A"; } else { for (int i: blockCondsMap[currentBlockName]) { blockConditionStr += condIdStrMap[i] + "OR"; } blockConditionStr.resize(blockConditionStr.length() - 2); } for (llvm::Instruction &instr: block) { switch (instr.getOpcode()) { case llvm::Instruction::Switch: { llvm::SwitchInst &switchInst = static_cast<llvm::SwitchInst &>(instr); std::list<int> condIds; for (auto &llvmCase: switchInst.cases()) { // cases std::string condStr = "("; condStr += switchInst.getOperand(0)->getName().data(); condStr += "="; condStr += llvmCase.getCaseValue()->getZExtValue(); condStr += + ")"; condIdStrMap[condId] = condStr; condIds.push_back(condId); std::string blockName = llvmCase.getCaseSuccessor()->getName().data(); if (blockCondsMap.find(blockName) != blockCondsMap.end()) { blockCondsMap[blockName].insert(condId); } else { blockCondsMap[blockName] = std::set<int>{condId}; } condId++; } { // default std::string condStr = "(NOT("; for (int i: condIds) { condStr += condIdStrMap[i]; condStr += "OR"; } condStr.resize(condStr.length() - 2); condStr += "))"; condIdStrMap[condId] = condStr; condIds.push_back(condId); std::string blockName = switchInst.getDefaultDest()->getName().data(); if (blockCondsMap.find(blockName) != blockCondsMap.end()) { blockCondsMap[blockName].insert(condId); } else { blockCondsMap[blockName] = std::set<int>{condId}; } condId++; } } break; case llvm::Instruction::Call: { llvm::CallBase &callBase = static_cast<llvm::CallBase &>(instr); std::cout << blockConditionStr << "\t" << callBase.getCalledFunction()->getName().data() << std::endl; } break; default: break; } } } } } return 0; }
ネストしたswitchには対応していません。ちょっといじれば対応できる作りにはしてありますが。
で、実行結果はこんな感じです。
N/A getParam (=x01) hoge (=x02) newHoge (NOT((=x01)OR(=x02))) piyo (NOT((=x01)OR(=x02))) poyo N/A foo N/A bar
作りは正直かなり雑です。switchで分岐する各BasicBlockごとに条件を割り振っているのですが、その合流後の消し方も同一制御構文から発生した条件がすべてそろっている場合は消す、という方法をとっています。条件の書き方もデータ構造を用意するのではなくstringでベタベタに書いています。そして、見て分かりますが判断に使用したオペランドの名前を取れていません。これはどうやらそういうもののようです。(LLVM get operand and lvalue name of an instruction - Stack Overflow)
今後についてはこれを継続するかどうか悩んでいます。これ以上進むとなるとまぁ、全Instructionの分析が必要になりますよね……私の実業務で困ったことではあるものの、そこまで労力をつぎこんでいいものかどうか……
- 参考にしました
Clang/LLVMのツールチェーンでControl Flow Graphを出してみる。
rutilicus.hatenablog.com
これの続き。
Stack OverflowでClang/LLVMのツールチェーンを使えばControl Flow Graphが出せるということなのでやってみた。ソースコードは承前の記事内のものと同一。
$ echo {bef,aft} | xargs -n 1 | xargs -I@ clang -fno-discard-value-names -emit-llvm -S @.c -o @.ll
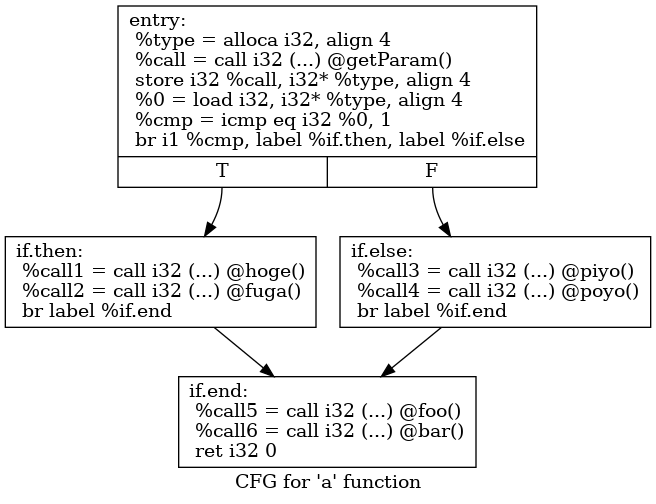
$ for name in {bef,aft}; do opt -analyze --dot-cfg "$name".ll; dot -Tpng .a.dot -o "$name".png; done出るのがこんな感じのpng画像。
- bef.c
- aft.c
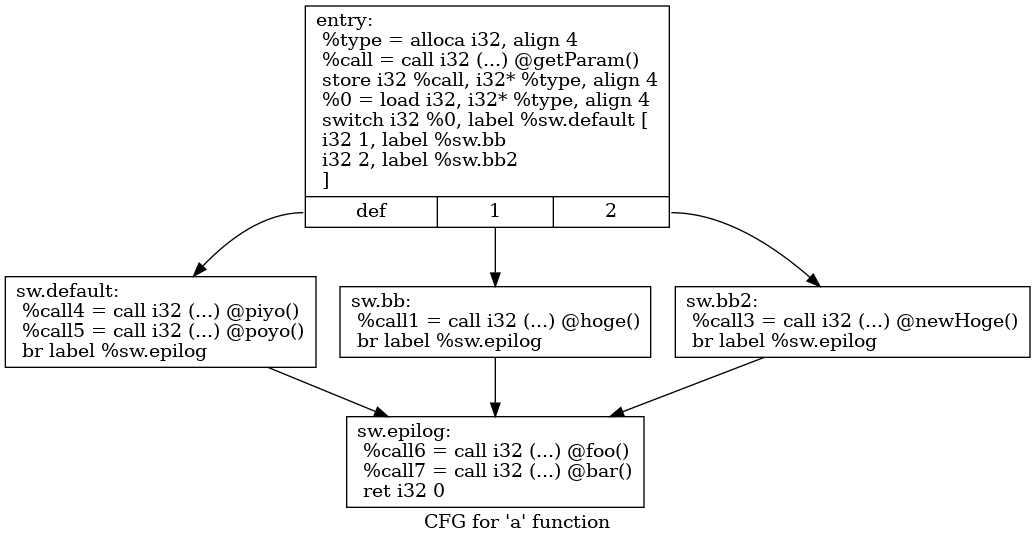
-fno-discard-value-namesオプションを付けることで変数名は残っていますが、それでもLLVM IRからオリジナルのソースコードの位置を出すのは骨が折れそうですね。Clangのオプション次第でLLVM IR内にコメントとして残せるのでしょうか。
Control Flow basedなdiffをとりたい。
皆さんはコードを先祖返りさせたことはありますか? 私はあります。*1
簡単に書くとこんな感じのことをやらかしました。
int a() { int type; type = getParam(); if (type == 1) { hoge(); fuga(); } else { piyo(); poyo(); } foo(); bar(); return 0; }
上記のコードを
int a() { int type; type = getParam(); switch (type) { case 1: hoge(); // oops break; case 2: newHoge(); break; default: piyo(); poyo(); break; } foo(); bar(); return 0; }
こんな感じにしてしまいました。
見た感じでわかると思いますが、
- メインブランチでtype = 1の処理にfugaの呼び出しが追加される
- type = 2の処理追加のマージ時にfugaの呼び出し追加の取り込みが漏れる
という事故です。この程度ならすぐわかりそうなものだと思いますが、このときは1KL超のマージ作業があり、かつif-elseがswitch-caseになることでインデントレベルがずれ、DIffも(空白を詰めるなどしなければ)まともに機能しないという状況でした。
で、このような事故をどのようにしたら防げるかなのですが、ある静的解析ツールにてControl Flowをベースにした比較機能があるということを知り、その方向で何かできないか模索しています。*2
どうやらGNUのツールでCflowというものがあるようなのでそれを試してみます。Ubuntuだとaptでインストールできます。
インストールして、冒頭の例の対応前コードについて出してみたものがこちら。
$ cflow bef.c
a() <int a () at bef.c:1>:
getParam()
hoge()
fuga()
piyo()
poyo()
foo()
bar()なんか思っていたのと違う気がしますが続行します。
$ diff <(cflow bef.c) <(cflow aft.c) 1c1 < a() <int a () at bef.c:1>: --- > a() <int a () at aft.c:1>: 4c4 < fuga() --- > newHoge()
流石にこのレベルだと単純増加ではなく関数呼び出しが置き換えられたという形で検出はできますね。
軽く触ってみた感じでは
- 大規模なコードに対して比較ができるのかどうか
- 計算式の一部が消えたなどのロジックの差分がとれないので、そこをどうするか
の2つが実用上の懸念点でしょうか。ロジックもControl Flowに出してくれるようなもので、かつテキストとして処理しやすい形で出せるものがあればいいのですが。
読んだ: 1日1問、半年以内に習得 シェル・ワンライナー160本ノック
gihyo.jp
今月頭くらいにシェル書く機会多いなーと思って買った本*1。こつこつやるべきかとは思いますが一気に読んでしまいました。以下感想。
一部バイナリの操作もありますが、基本はテキストの操作です。テキスト操作時の基本はだいたいawkとsedなので、手を動かして進めていればこれらの扱いには慣れます。最終行を抽出するだけなのにわざわざawk書いていたあの頃の自分にsedを使うことを教えてやりたい。
- あまり使わないコマンドには慣れないかも……
扱う内容の中にはバイナリ解析やJSONのレコード選択、MeCabを利用したルビ振りまで(!)あるのですが、頻出する内容ではないのでどうしても通して読んだ際の印象は薄いです。こういったものは調べればできる、というところまで持っていけていたらいいんですかね。
- 追加でインストールするコマンドがそれなりに使われている
進めているとaptで追加インストールするコマンドを利用することがそれなりにあります。大体はどの環境にでもあるようなコマンドで処理する別解も記載されていますが、やはり専用のコマンドに比べるとどうしても冗長になります。目次を読んでまさにこの処理がやりたいというのがあった場合でも、特に業務で使用する場合は使用する環境に適用可能かどうか事前に確認しておいた方がよいかもしれません。
こういったコマンドでの操作に慣れることはコンソールでの操作の可能性があるのであれば一度はやっておいても損はないかと思います。その題材は別に本書でなくてもよいとは思いますが……何か題材ありますかね。
*1:今は書く機会がめっきりなくなってしまった